By Matthew Stephens
Pagerank is Google’s renowned algorithm and foundation of Goolge
How Google Search Works
- Index (giant library of search)
- 1. Try to understand what you’re looking for
- 2. Shift through millions of matchign index —> page with most relevant info on top
- factors:
- Page containing words you’re searching for appear on top
- Location of words (cpation/title)
- Look at how pages link to each other to see what pages were about
- Location, where a search happens
- (Italy—> lasagna festival)
- When page uploaded (more recent —> more accurate)
- Page containing words you’re searching for appear on top
- factors:
- 3. Detects spam
When search results happen, they happen instantly
- But actually behind the herd, there is an indexing process that might’ve gone for days and days, collecting info about web pages and storing them, and allowing these queries to happen very fast
Program that uses indexing and querying classes to search through a data base of wikipeedia articles
Types of
- Small wiki (mBs)
- Medium wiki (bit bigger)
- Big wiki (~200mB)
- Can take an hour to index all information
Search can be performed with/without the use of the page rank algorithm (pagerank = determining authority of each document)
- You can search without page rank or linking method
When program run without : runs on determination of relevance between pages and documents
__________________________________________________________________________________
Bad way to program a search engine:
Method:
– Type in query
– Program transverses the entire corpus(=library/data holder of documents to search through) until appropriate pages are returned
Disadvantage:
– if you’re searching through billions of web pages, just looking for all the pages that are related to certain word might take forever
– also takes up a lot of space because if searching through the pages requires lots of documents to be stored –> more space to store al the documents –> more space to find pages related to it
∴ Bad time and space complexity –> uses a lot of energy
Good way to program a search engine:
Method:
– Divide work into subsets via querying and indexing
– groups are divided into classes (= classrooms, one classroom has little workers for that specific class)
–> interfaces that link two classes together
– index class will sort through pages, storing data about content of each page (such as pageID, page title and words)
– can take any amount of time (couple of seconds ~ days depending on size of data)
– query will use the information from “hardworking” index class to return search results extremely quickly
– after little workers index through results, throw out the important one (= relevant, information) into hallway and query picks up
(basically query and index work together)
∴ Good space and time complexity because query (users are involved) don’t see the hard work during the index, just see the search and the search results.
– however, does take up a lot of data (reason why Google has numerous data centers), but is MUCH more efficient for the user
__________________________________________________________________________________
Index:
- Sort through data
- Store identifying information about all pages (document ids and titles)
- Store various scores related to pages (page rank scores)
- Known as “preprocessing step” —> could take days (when millions of pages to be indexed)
- —> kitchen – the chefs
query:
- Handle user’s query
- Perform appropriate
Program structure:
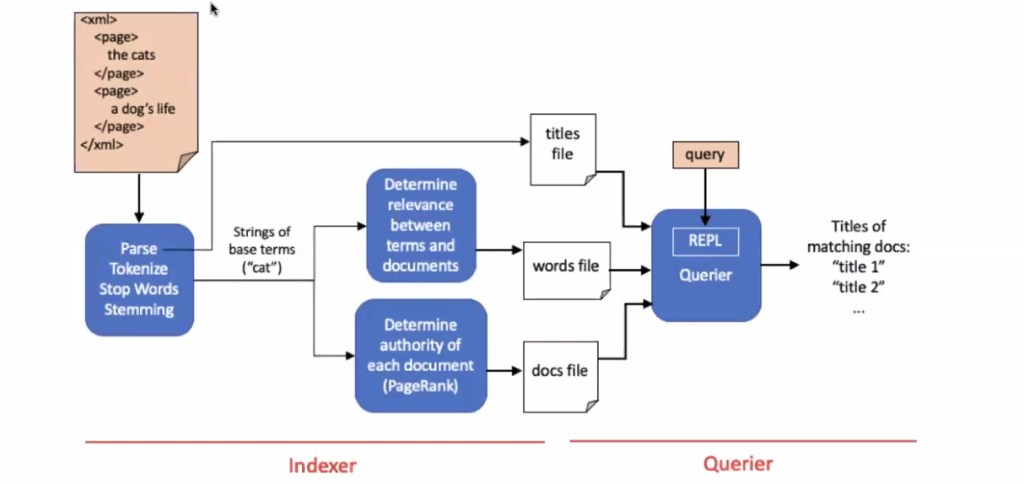
- Xml format (orange)
- have page, information of page, terminology to close page
- Another page, information about page, and closing page
- Xml, Pageid, page title, page information
Then these pages are put into indexer (next blue)
- indexing process:
- Parse : going through entire xml (sort, and break xml and zoom information on the pages themselves)
- Extracting text from XML format (parses through XML)
- Tokenize : removing punctuation and white space
- How many cats in Siberia!! = How many cats in Siberia (have to tokenize search to just zoom in keywords)
- Stop words : removing stop words (“like”, “the”, “that”)
- Remove words for algorithms to work better
- But page rank is mostly in English (so a bit inconvenient for other languages)
- Stemming words: “running” —> remove ing to “run”, want to focus on stem words (don’t care if ran, running)
- Parse : going through entire xml (sort, and break xml and zoom information on the pages themselves)
(for stemming words process):
Some words can be “s” words (he swims —> swim), but what if you have a word that finishes in s? (ex. walrus —> walru???), but artificial intelligence and machine learning help get gist of it
- Wouldn’t it be much more intelligent to use limitation rather than finding stem words?
- Just taking base words —> simpler form of limitation
- Studies —> stud (less efficient than study)
- Limitation would need a neural net to identify the word and relate it to the word that we’re looking for
- Just taking base words —> simpler form of limitation
After all done this, determine the relevance between terms and documents without using page rank
(Query: how many cats in Bay Area —> find simply relevance/how is the cat related to all of the documents, cite “Bay Area” to all documents we have)
Decode the links specifically using page rank algorithm (looks at links to and from pages, and determine authority of each page)
Put all information into documents (little algorithm will work out of classroom and put it into hallway that query can use to quickly and efficiently extract information when search entered)
Authority : how important a web page is
- (a webpage by Yale vs a web page by MatthewStevens.com for topic about lecture)
- Yale is more authoritarian because probably linked to more research papers and other pages (people quoting)
- Just because a page has more links —> more authoritative, or more important linking to a certain page link
Indexing – part one (no page rank)
- Term frequency (number of times each word appears in each word —> normalize)
- Calculate the term frequency (a.ka tf) = count of how many times word appears in document
- Call the count of a specific term in a specific document “x”
- However some documents are longer than others
- solution: normalize the number of counts per document
- Dog appears 100 times —> larger than one in one
- solution: normalize the number of counts per document
If we just counted the number of times a word appears in a specific document, then that would be a worse document than a document that has only five times but much shorter (most frequently occurring word and use that as a BASE to determine how long a document is, don’t want to be prejudiced against short documents)
Size: most frequently used term

word: tea
- Only have two documents in entire library
- Tea appears 5 times in doc 1 (100 words long)
- Appears 100 times in doc 2 (thousand words long)
- If not normalize, doc 2 would be returned first because has tea more often (but don’t want to judge smaller document)
- Count the number of times the most frqueenly word in each document appears
- Doc1: “lightbulb” —> 10 times (5/10= 0,5)
- Higher term frequency
- Doc 2: “sport” —> 10000 times (100/10000 = 0.1)
- Doc1: “lightbulb” —> 10 times (5/10= 0,5)
- If you divide by bigger denominator =-> term frequency smaller
- Reason: up scores of frequency documents
Why we use most frequent word rather than total number of words?
- Because we are stemming, tokenizing and removing stop words —> limited number of words
- But if its’ a spam page, the word lasagna could be counted a 1000 times —> we would be counting the words that we liked for specifically, so want to pinpoint a different word
Tf = x/y
- X = word being searched for
- Y = number of occurrences of most frequently used word in doc
The problem consists of slightly more dimensions because have to keep track of $ of times a word appears in a particular document
so when coding, keep in track of two variables (xij, and y ij)
If one word on document 1, document 2, document 3
- Inverse document frequency, pd
- scale up term frequentcy of words in fewer documents (rarer words)
- Helps to ensure that particular words don’t drown into the sea of pages and help words
- Don’t want to drown the words into other document that have saimilar words since the rarer words would have lower frequency score
- Calculation:
- N = # of docs in corpus
- I = word in corpus (rare word)
- Ni = number of documents containing the word I
- idf = log (n/ni)
- Divide by smaller denominator
- Log because the number can become very large
- n= million, one word in 10,000 —> very large number
